Designing supervised ML workflows to make a Data catalog AI-powered
Saves money on buying a different AI product, also 2/3 of all our customers purchased this software
Why this product exists
Utilizing our customer data sets, we can build a Catalog which goes beyond just being a directory, and becomes a learning system
Most modern enterprise organizations use Microservices, leading to fast, scalable products & efficient engineering. This distributed model also means each team manages its own data, giving rise for the need of a Data catalog to consolidate the systems & metadata.
Challenges with discoverability, data silos across different sources, and dependency on multiple teams to access data are resulting problems which traditional catalogs have made attempts to solve.
Now, using customer-provided metadata/labels like PII type, the classification algorithm can be trained to reason, be better, and offer insights with high confidence.
Tradeoff: Choosing speed over polish, reduced rework later
Data analysts and Data engineers are the product's high level audience
descriptive → searchable → browsable
labelable → trainable → improvable
Old catalogs vs Transcend
How might we through labeled metadata & human-in-the-loop workflows build a Catalog where success is classification precision & recall, not just discoverability?
Why it matters
Data engineers & analysts confirm that Data catalogs fail at accuracy without supervision
Business value such as identifying users that about to churn, and swiftly taking actions to retain them can be derived, thus saving money on customer acquisition costs.
Onboarding
From Onboarding to the Aha moment
Triggers after the first database ingestion
Empty state

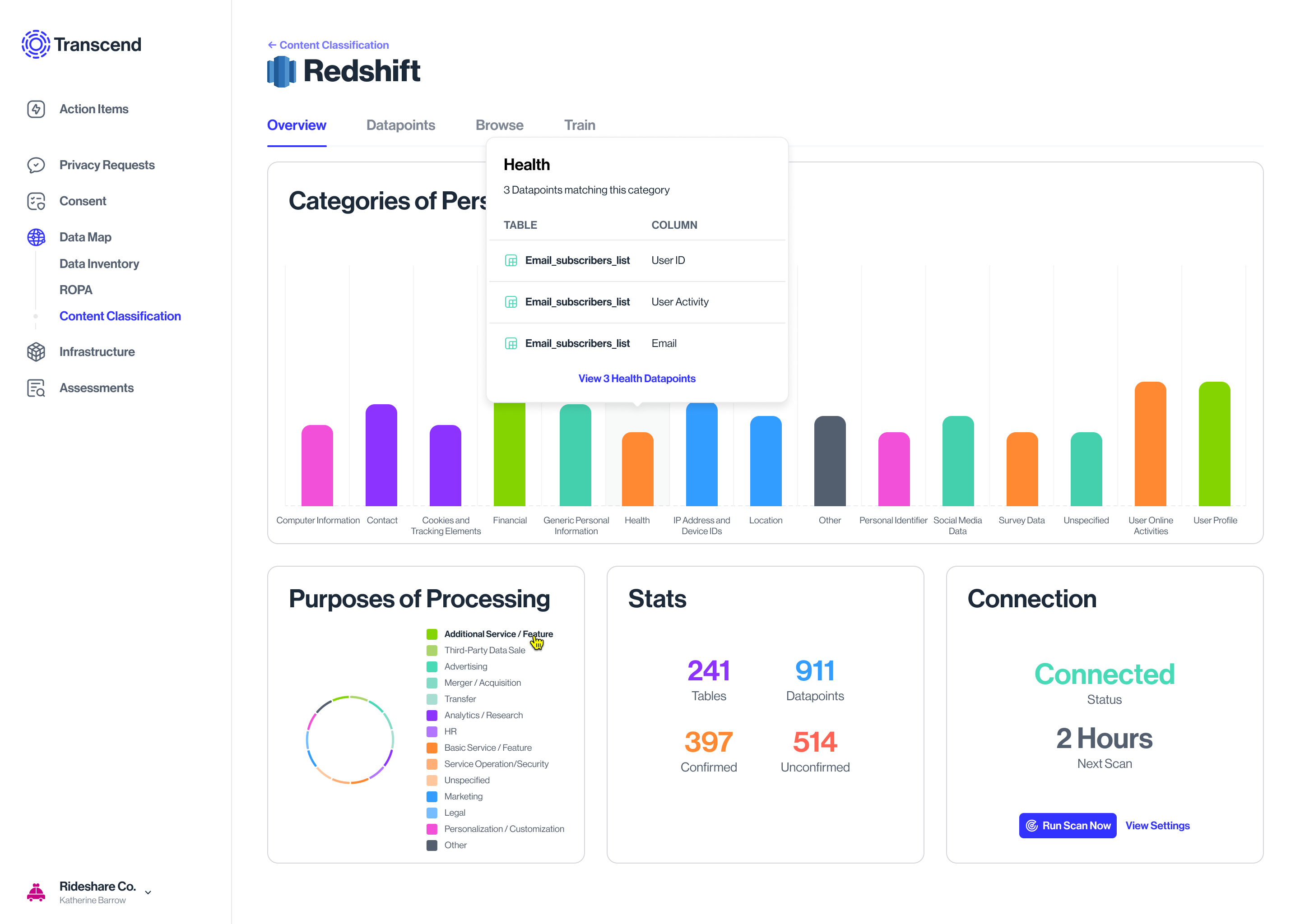
Classification explainer
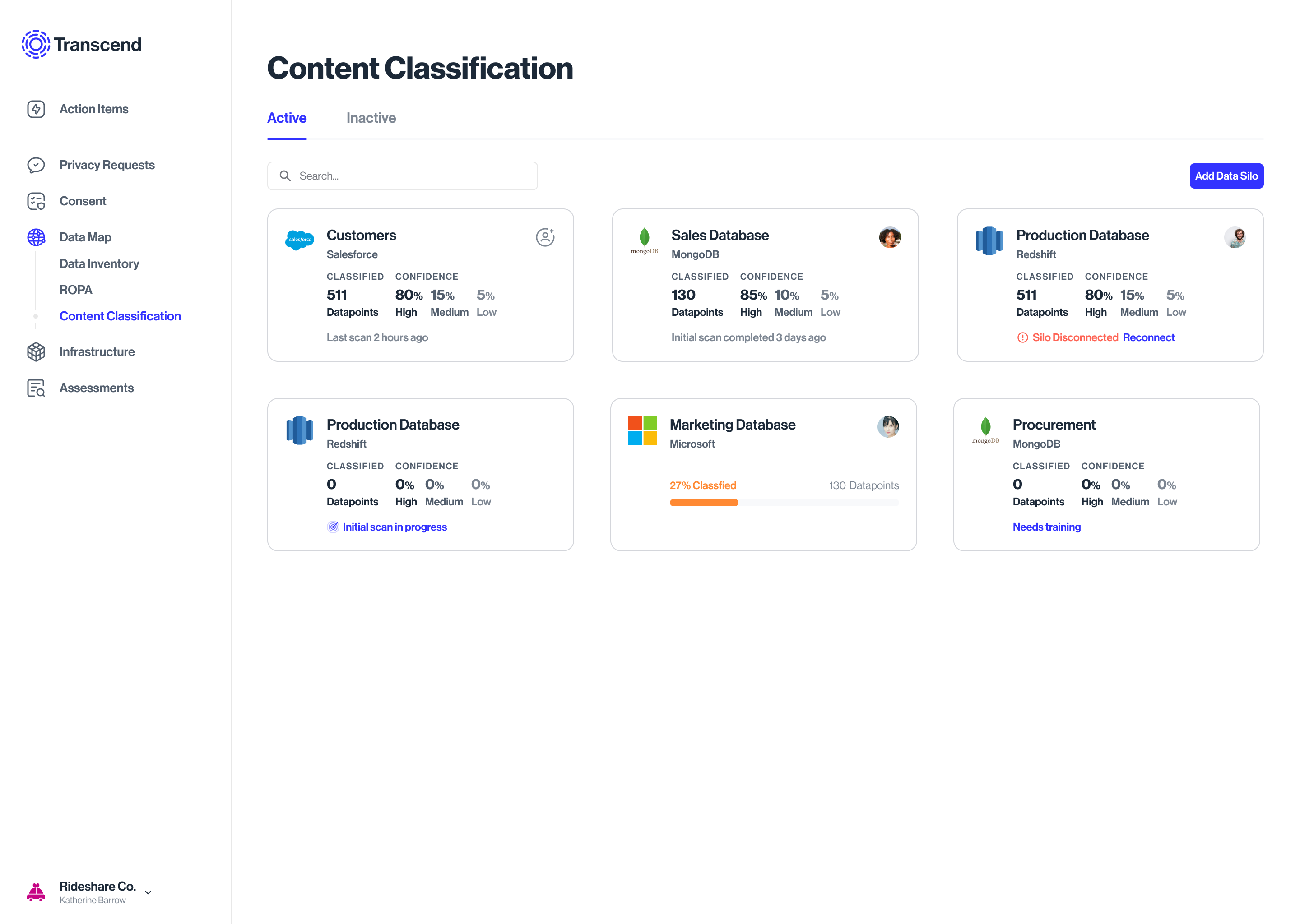
Datasets & sources
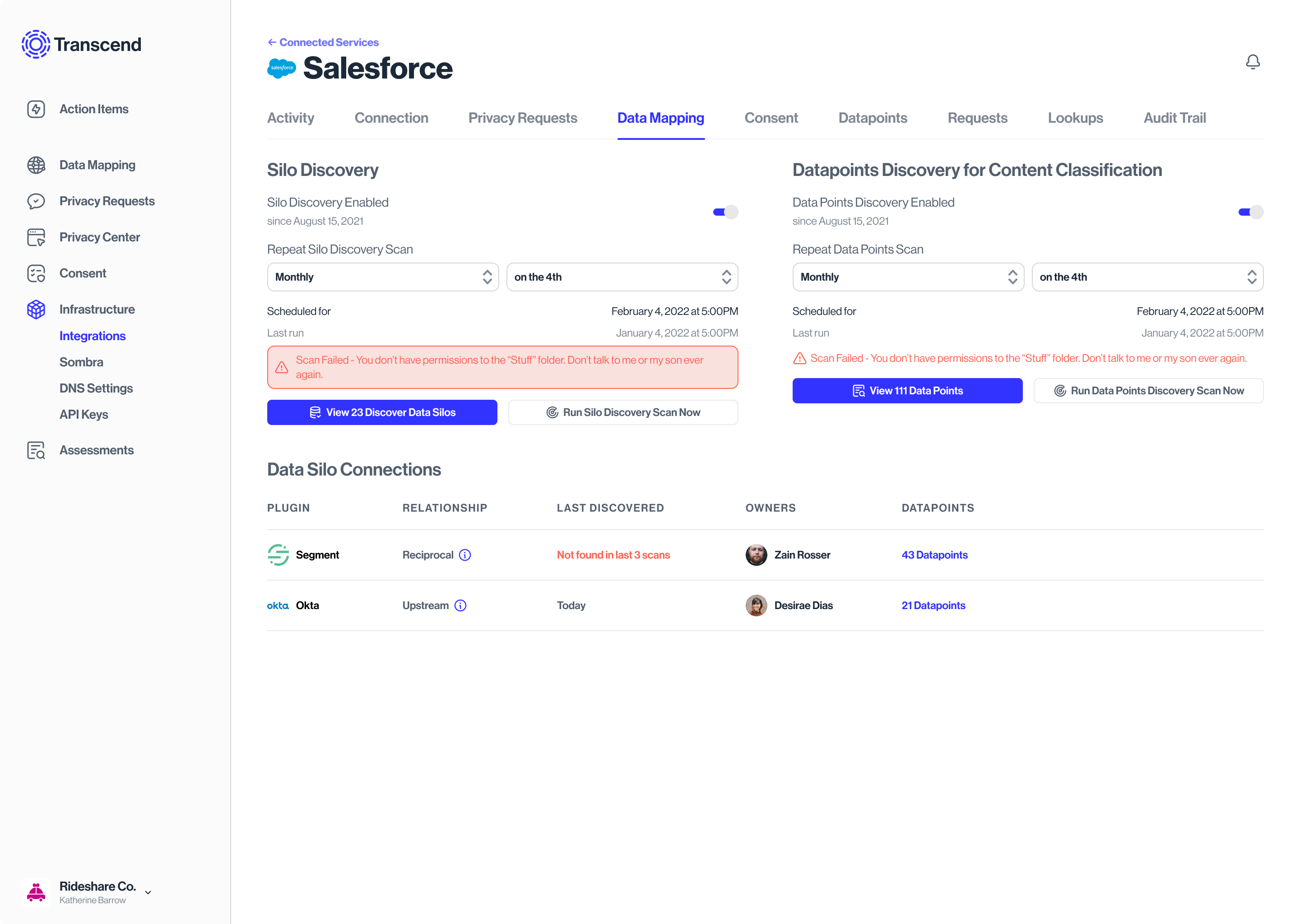
Ingesting databases, browsing files, and scanning protocol
The scanning protocol sets how often the Transcend algorithm gets trained by customer data

Browsing through a fully ingested db

All database states
Scanning protocol

Other table states
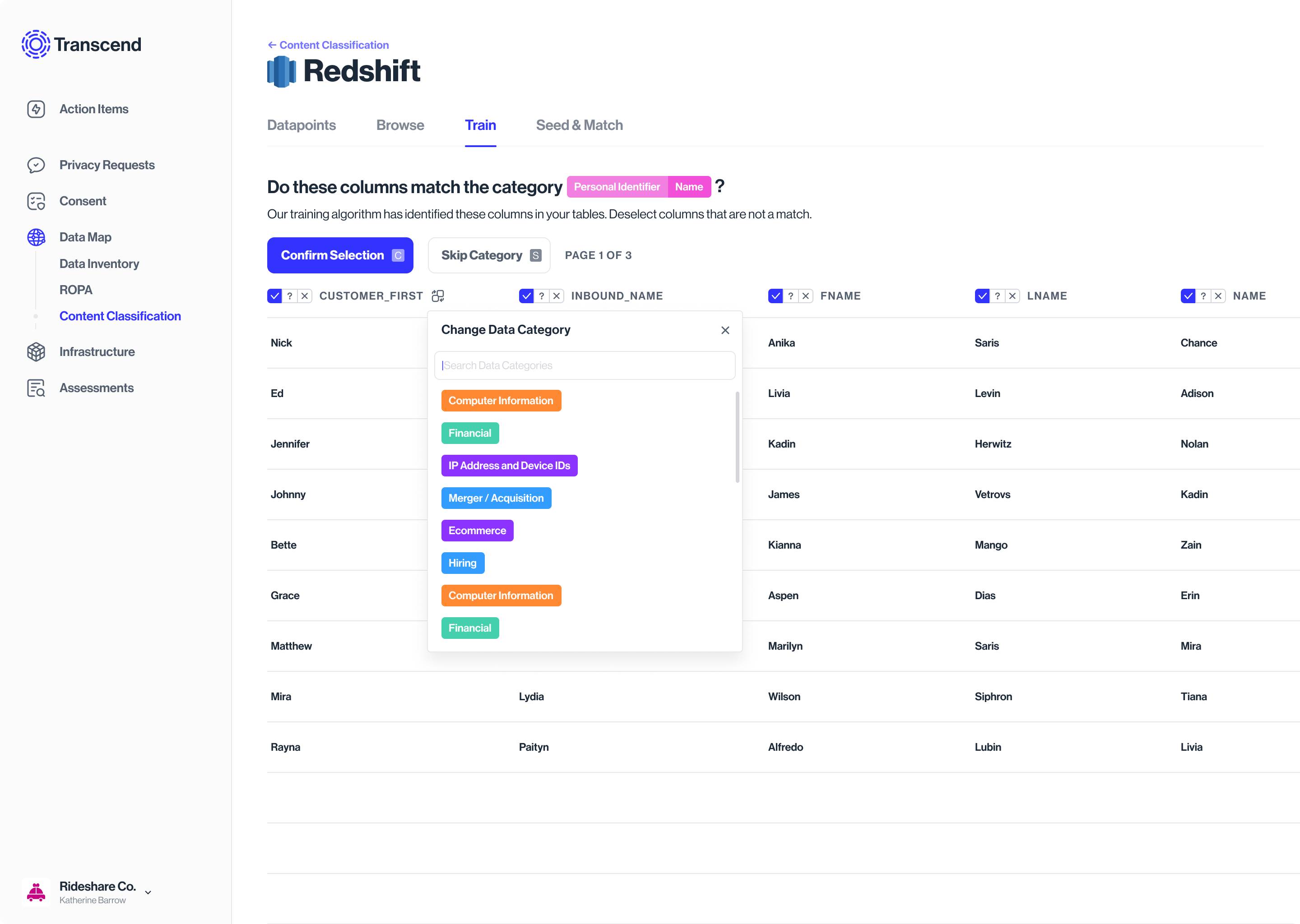
Algorithm training
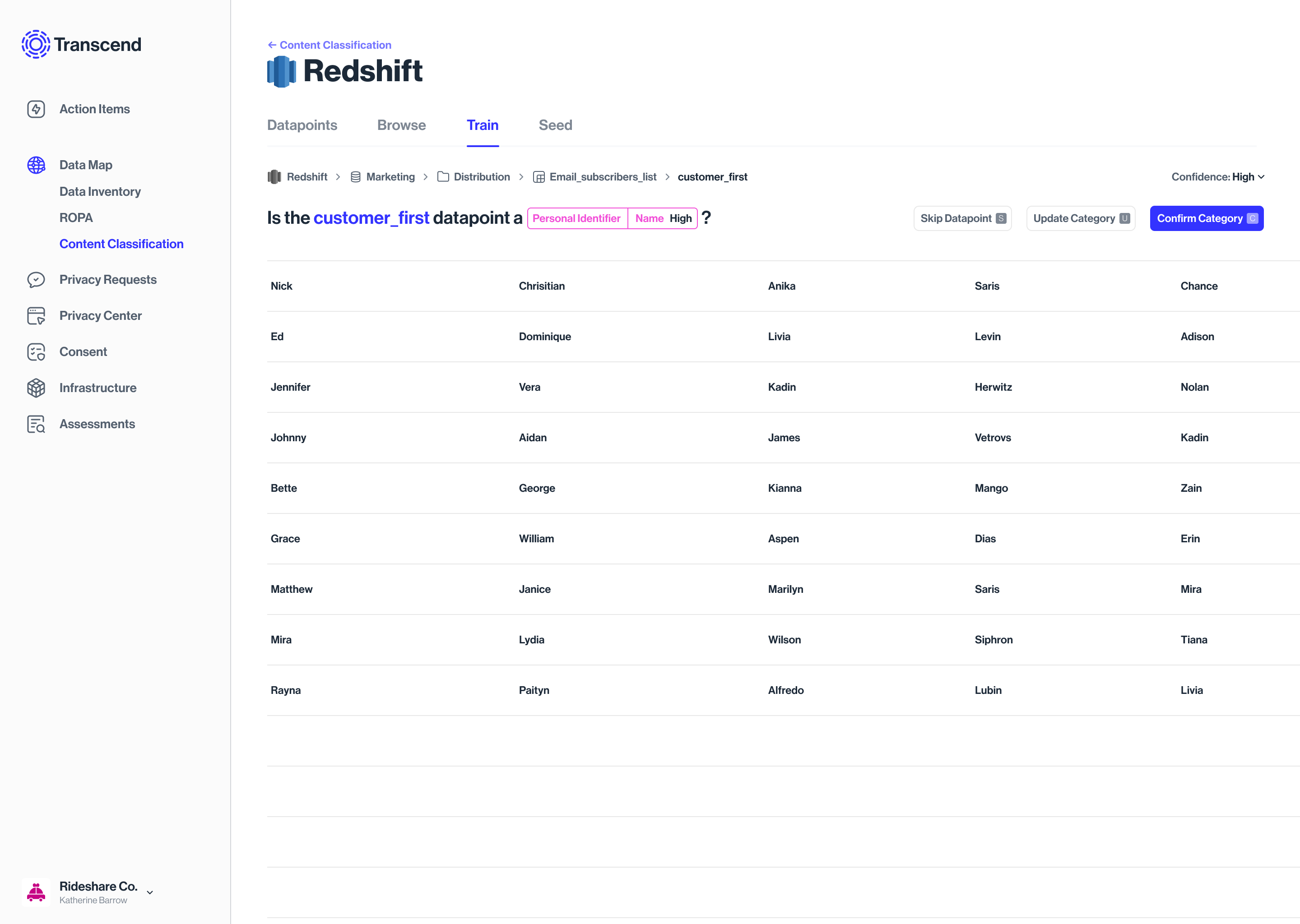
The model detects, tags similar metadata across datapoints, and suggests a classification into categories
Accepting or rejecting the label is the supervisory training of the model. The algo then knows to recognize & classify the rest
This could be a Yes/No/Not sure
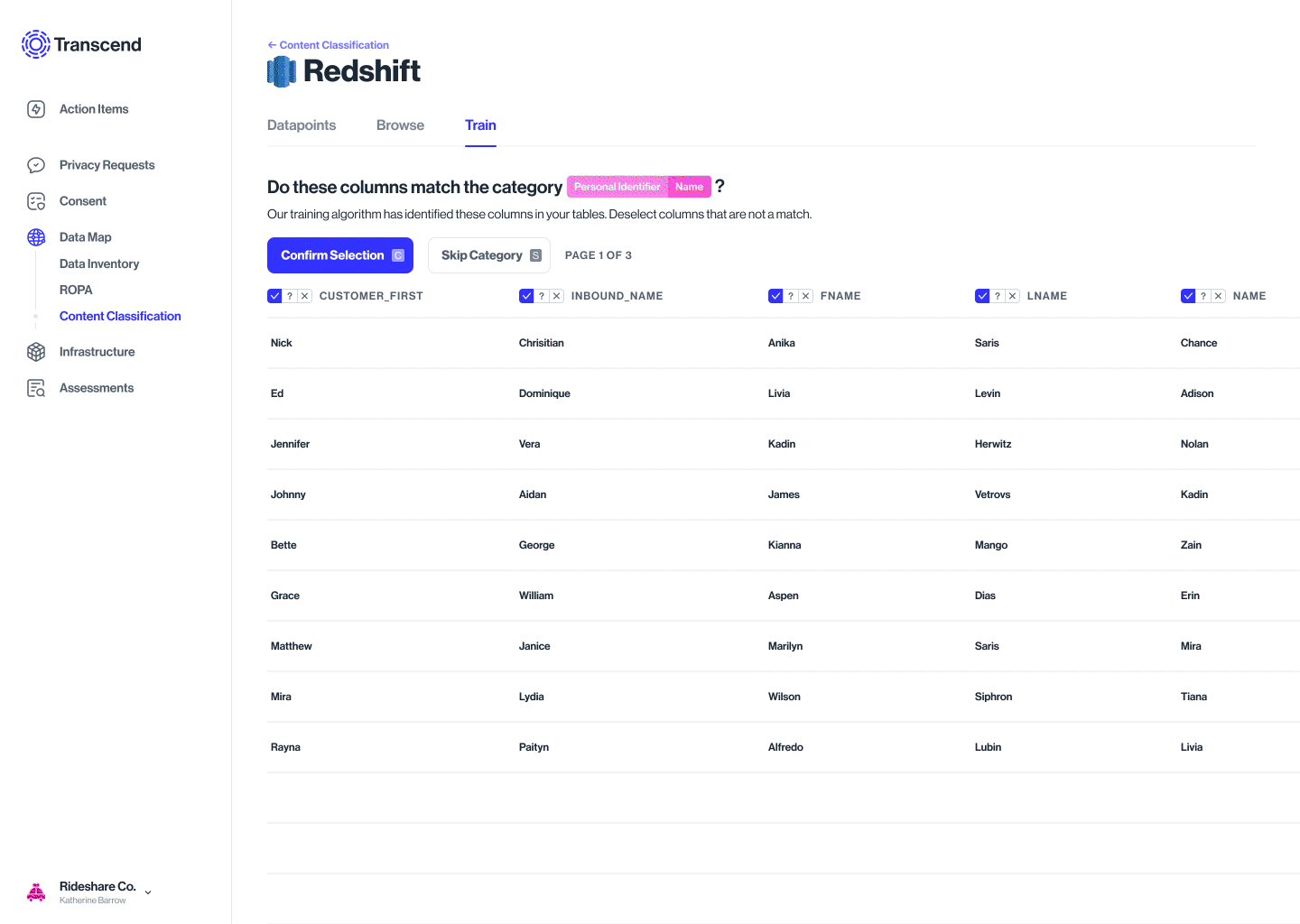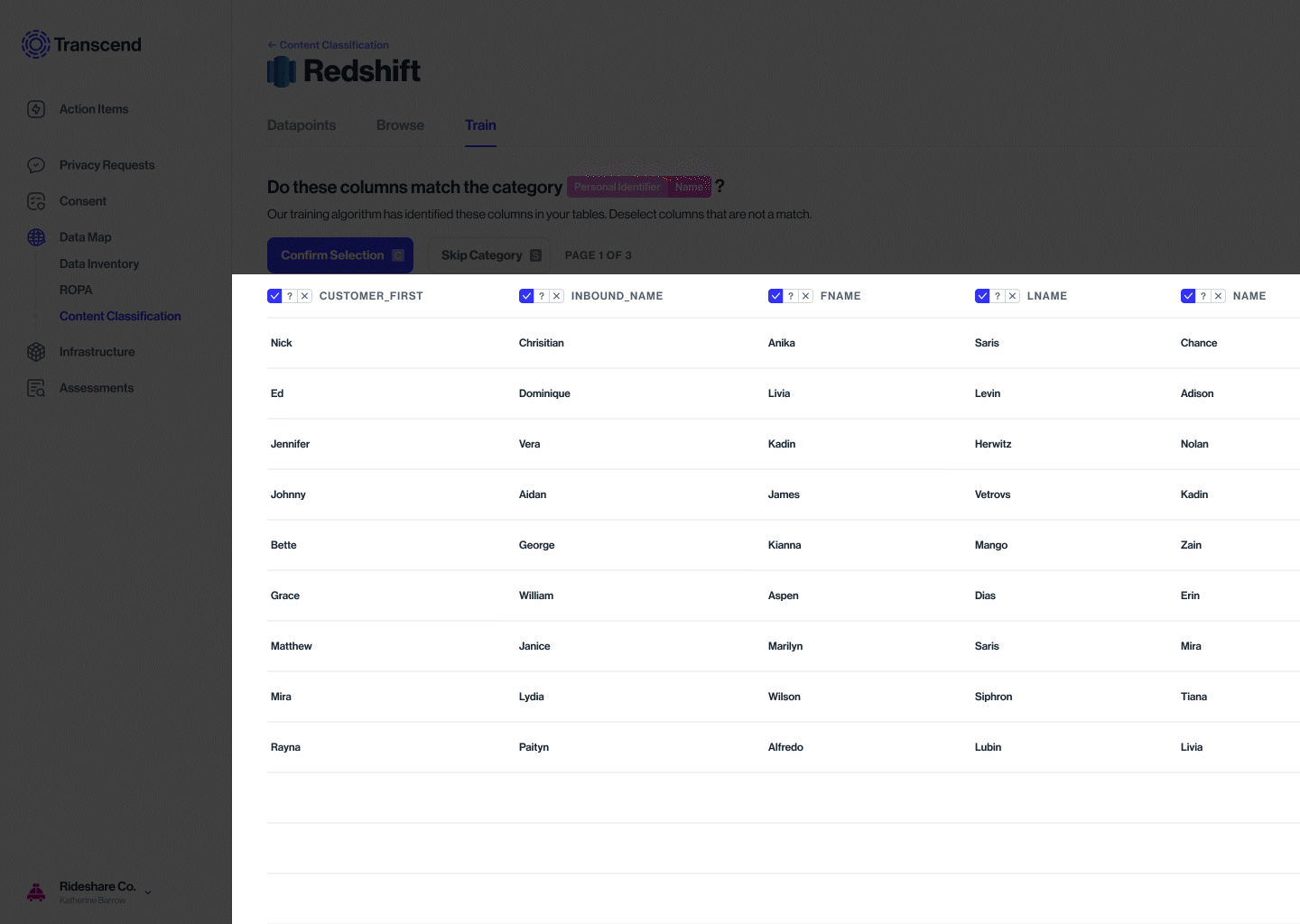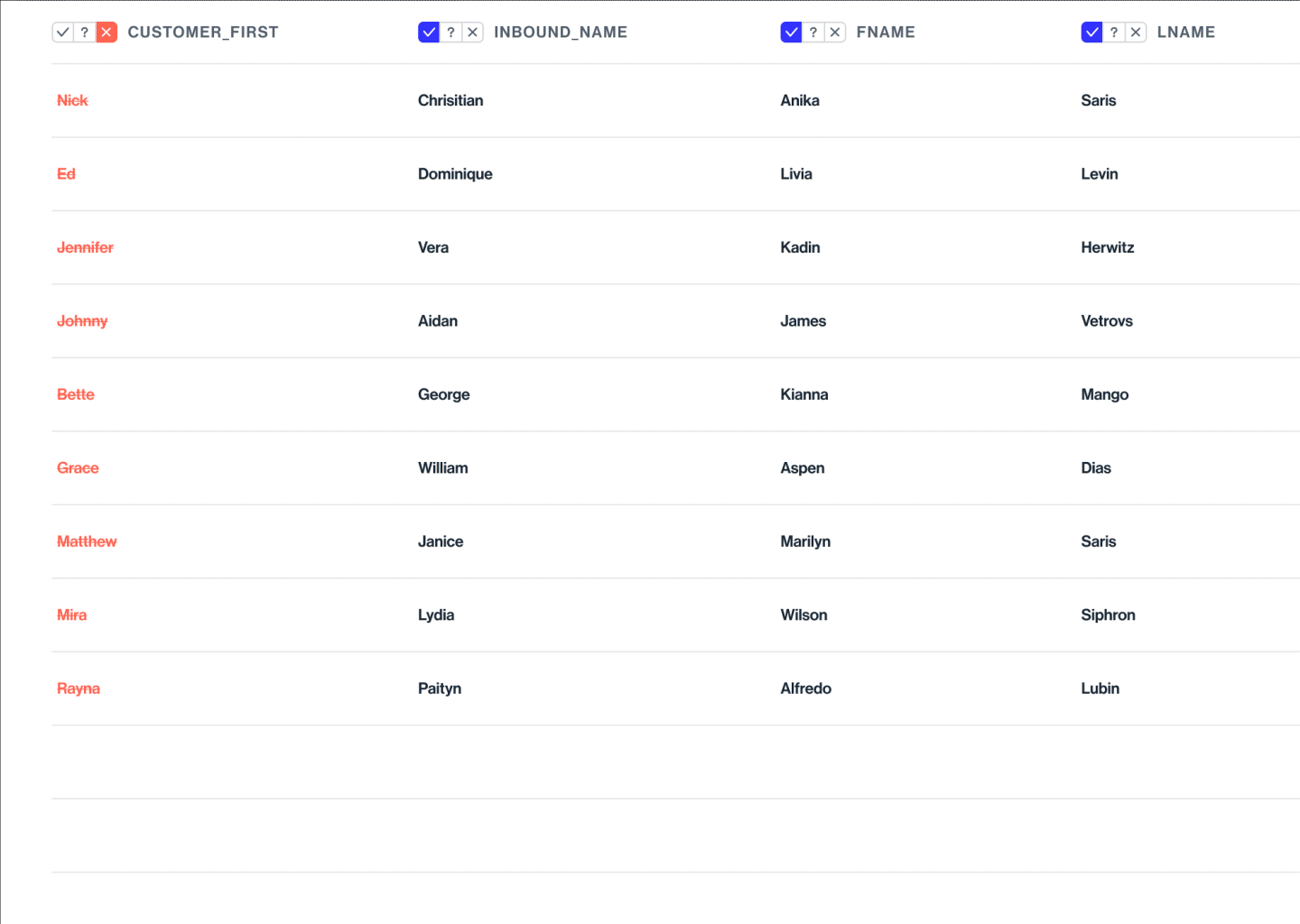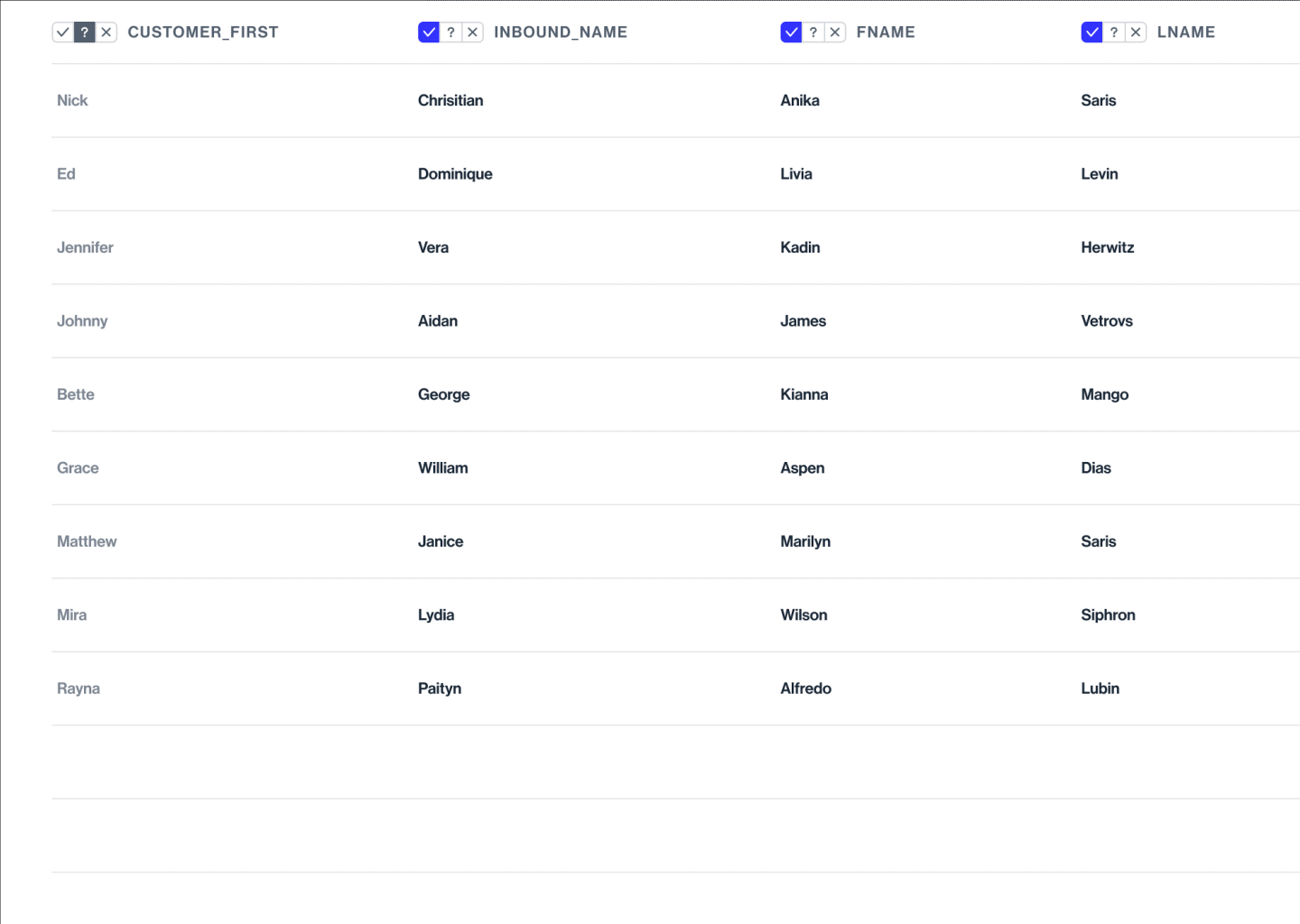
Expected user actions
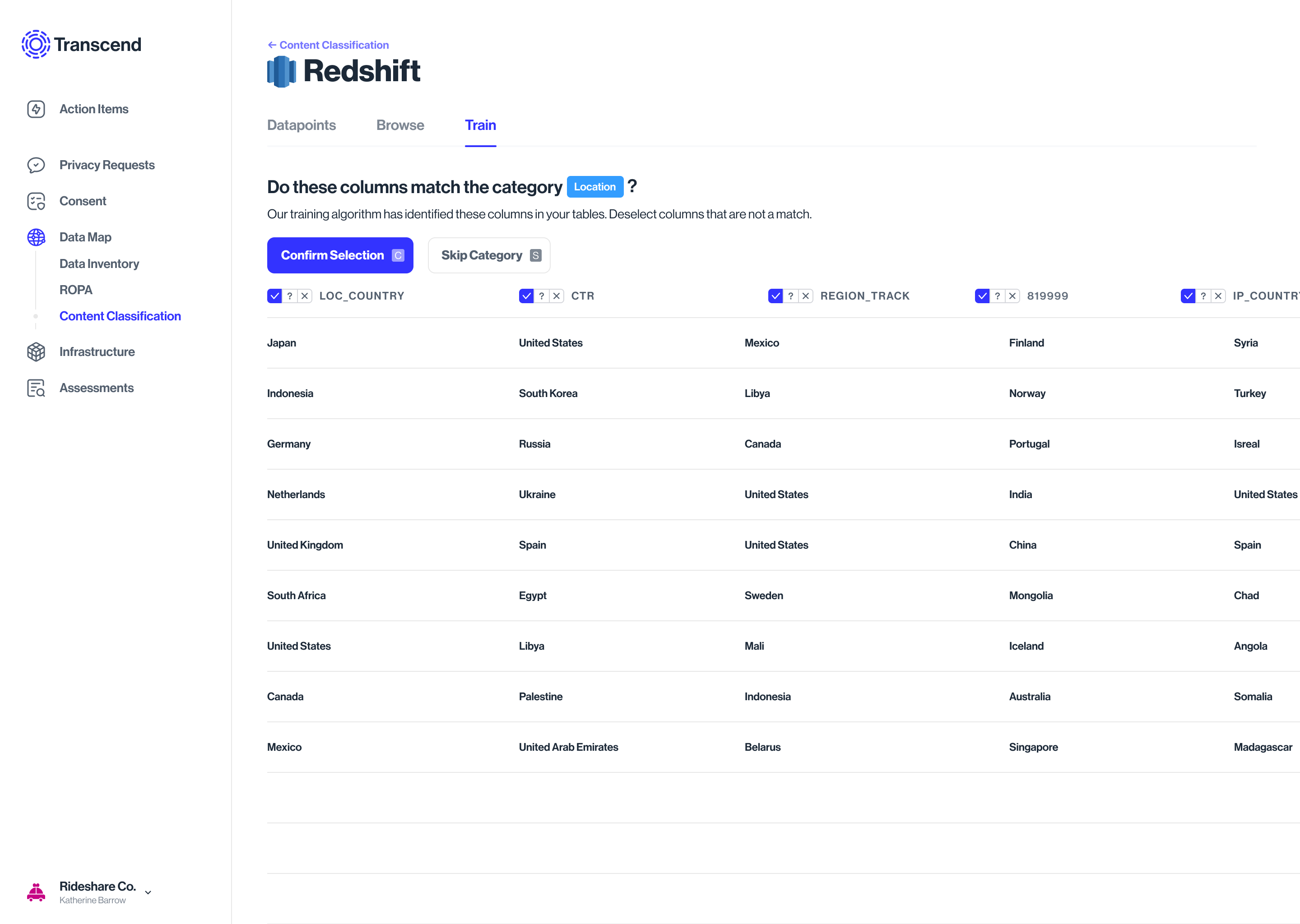
Training tab
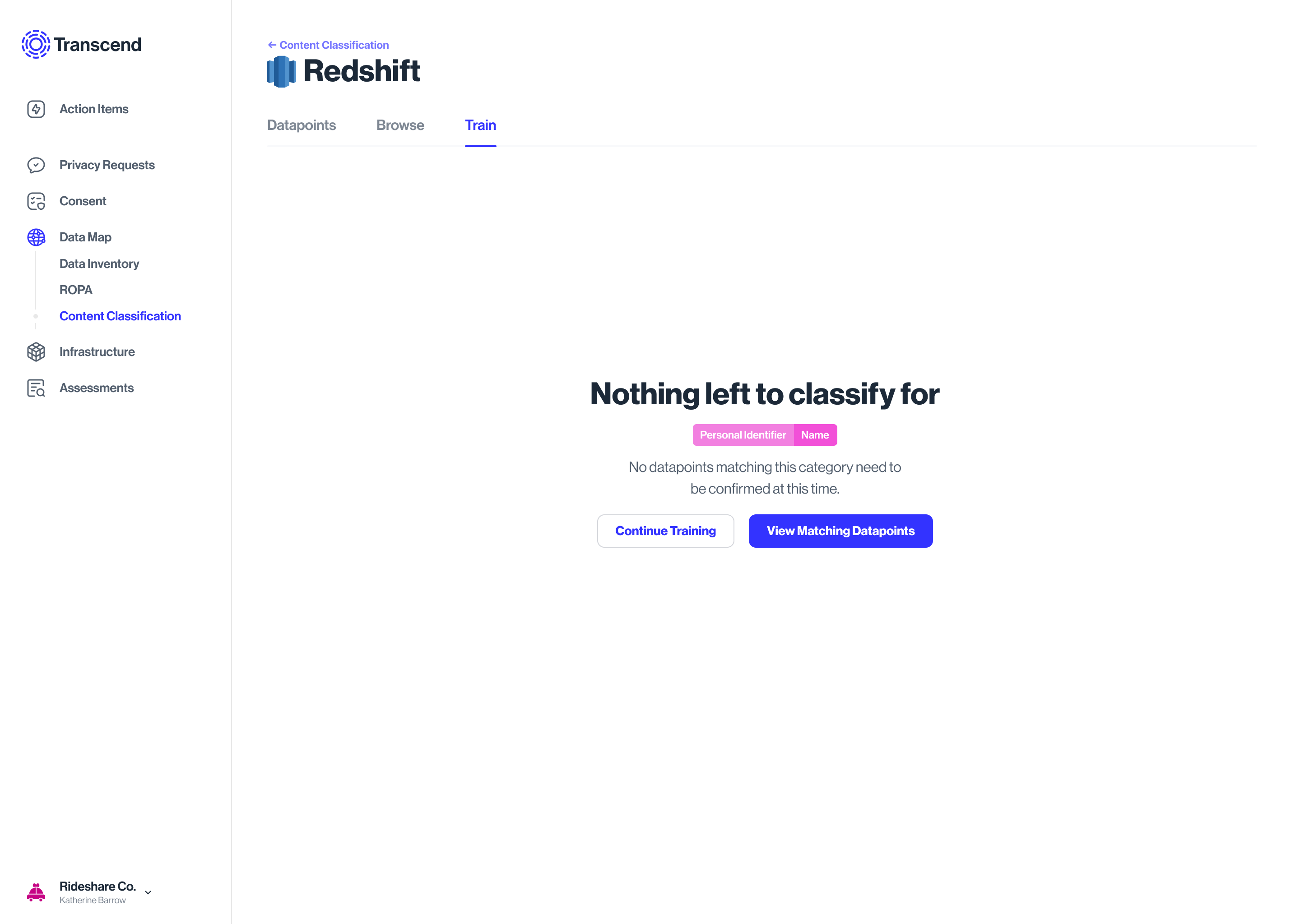
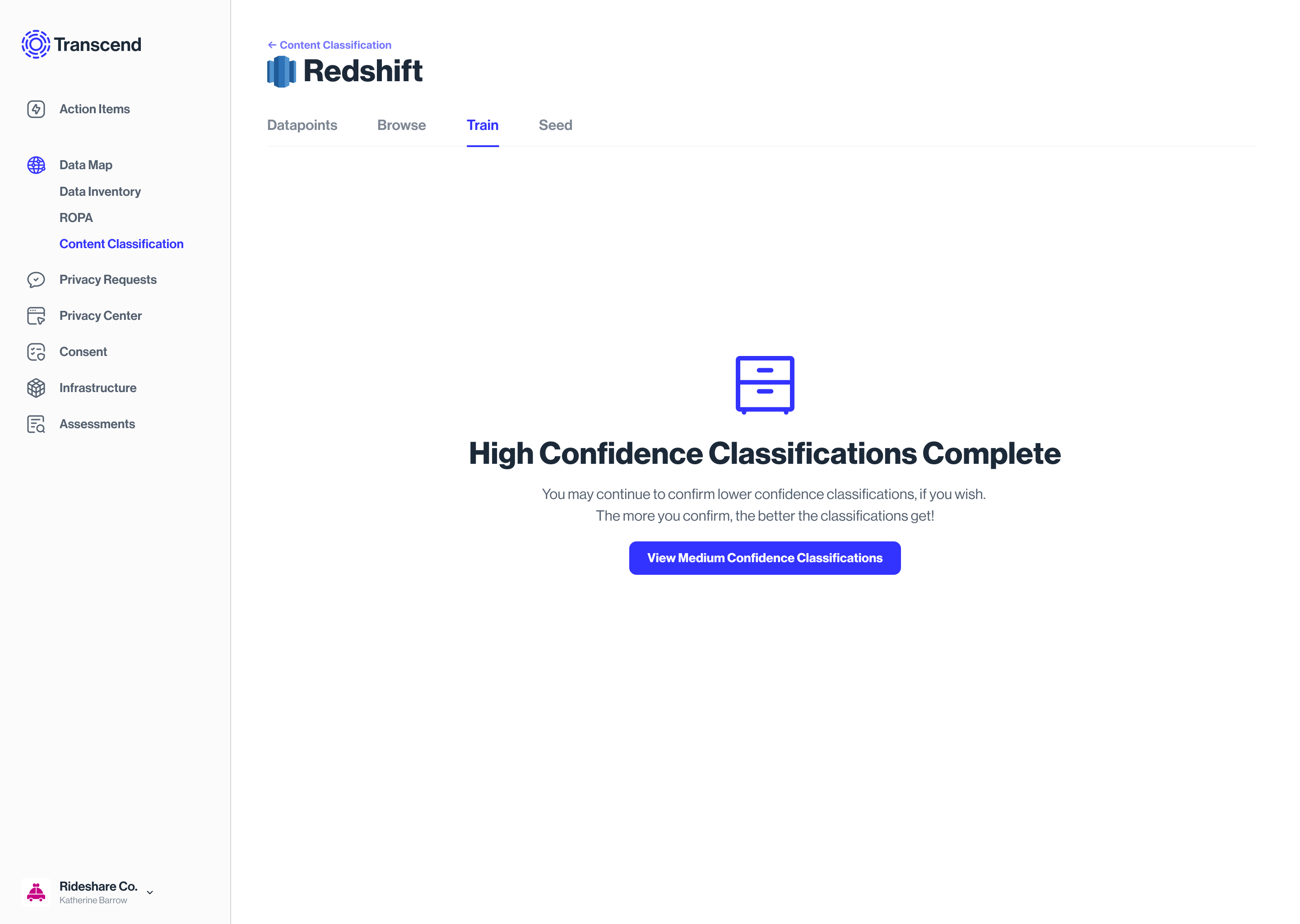
State: Datasilo classification is complete
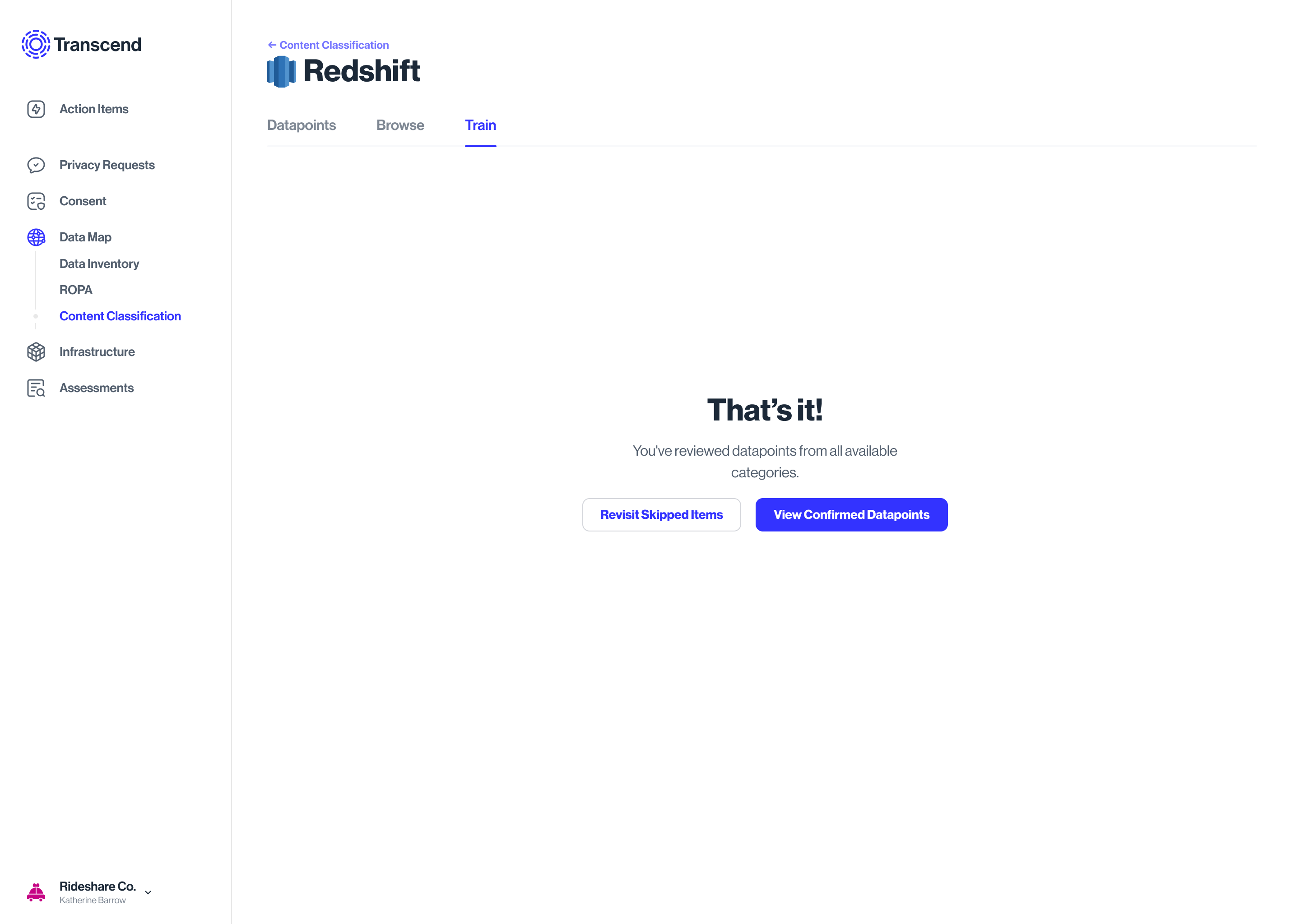
State: User skipped some classifications
Changing the category suggested by the classification model
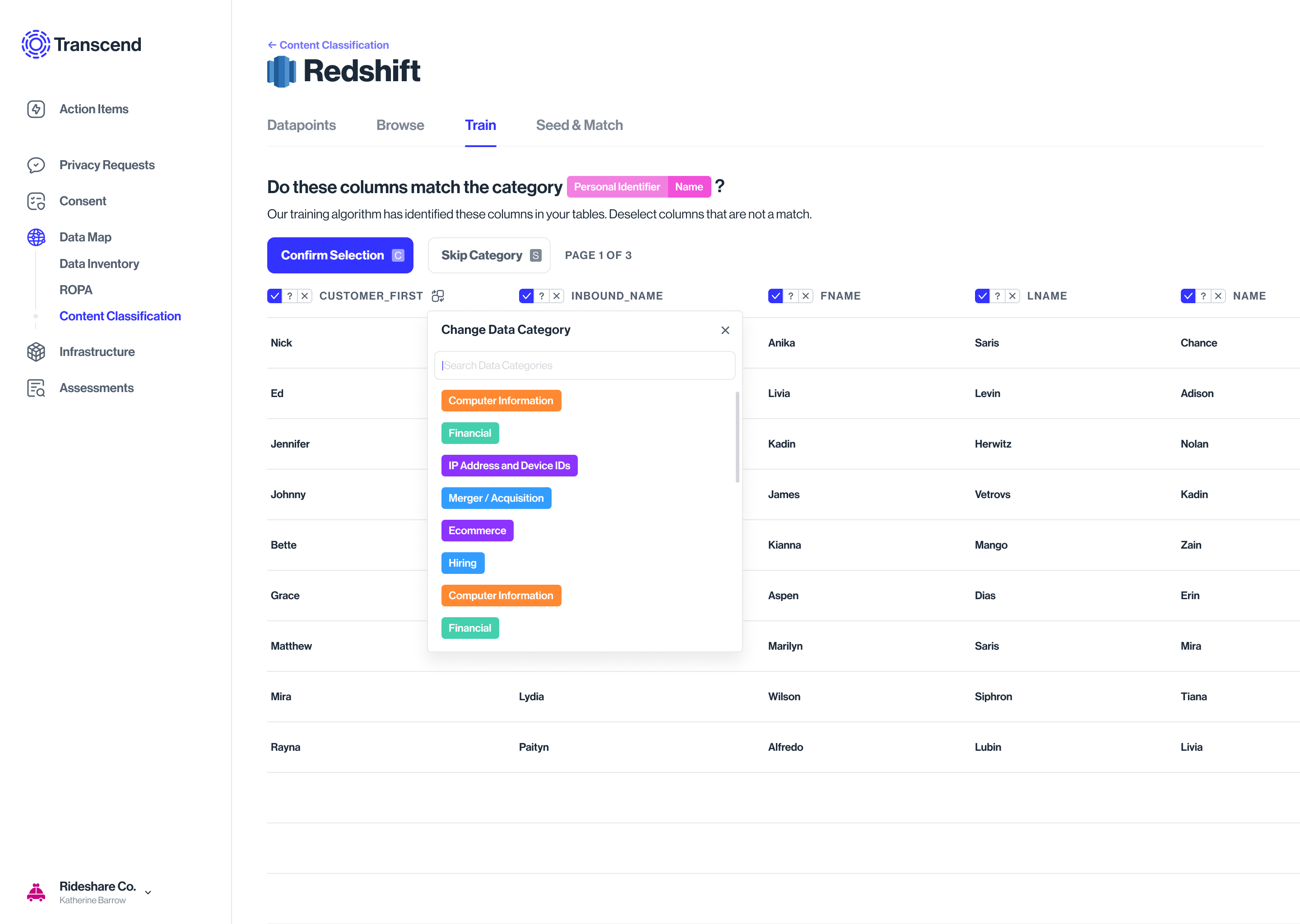
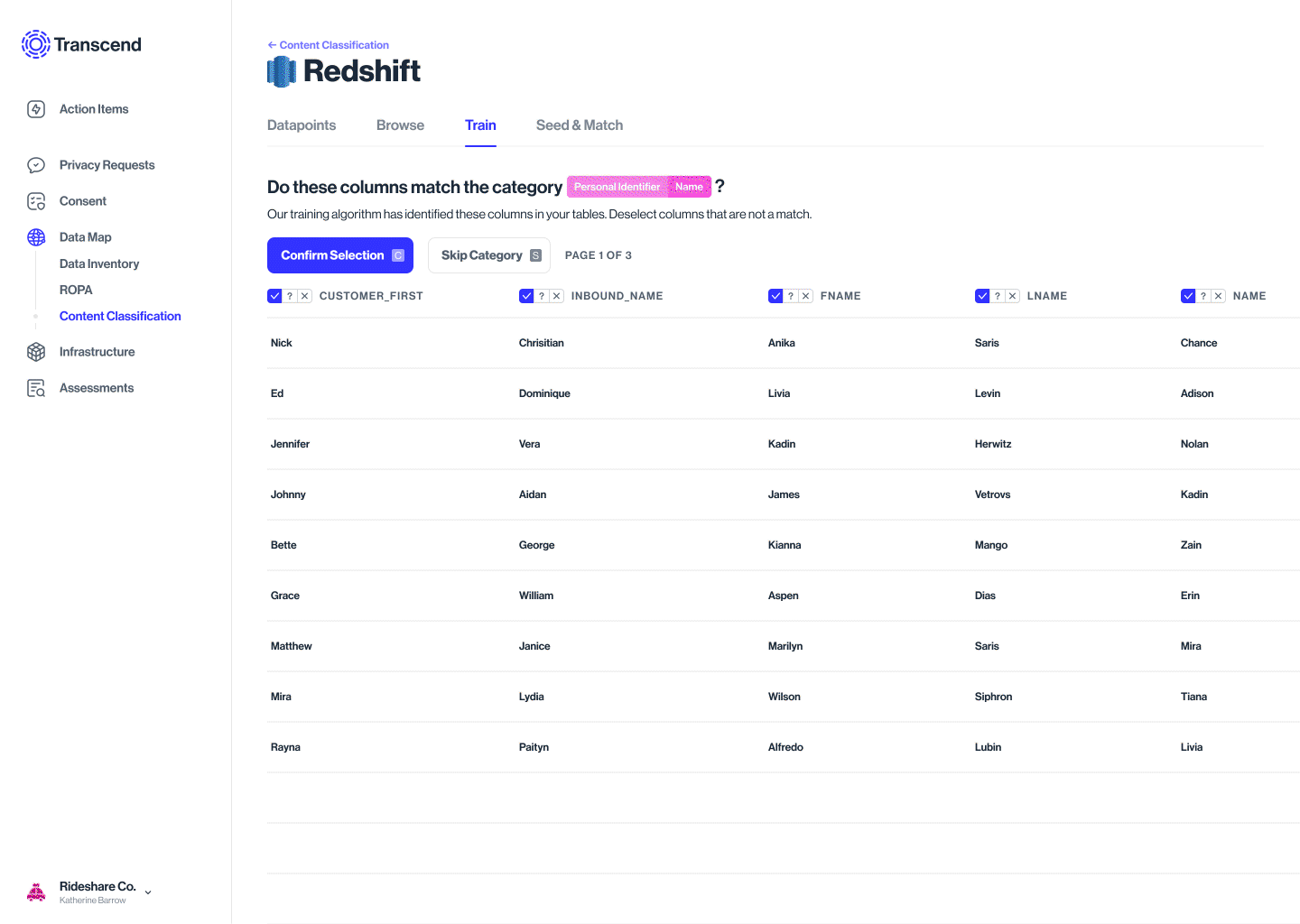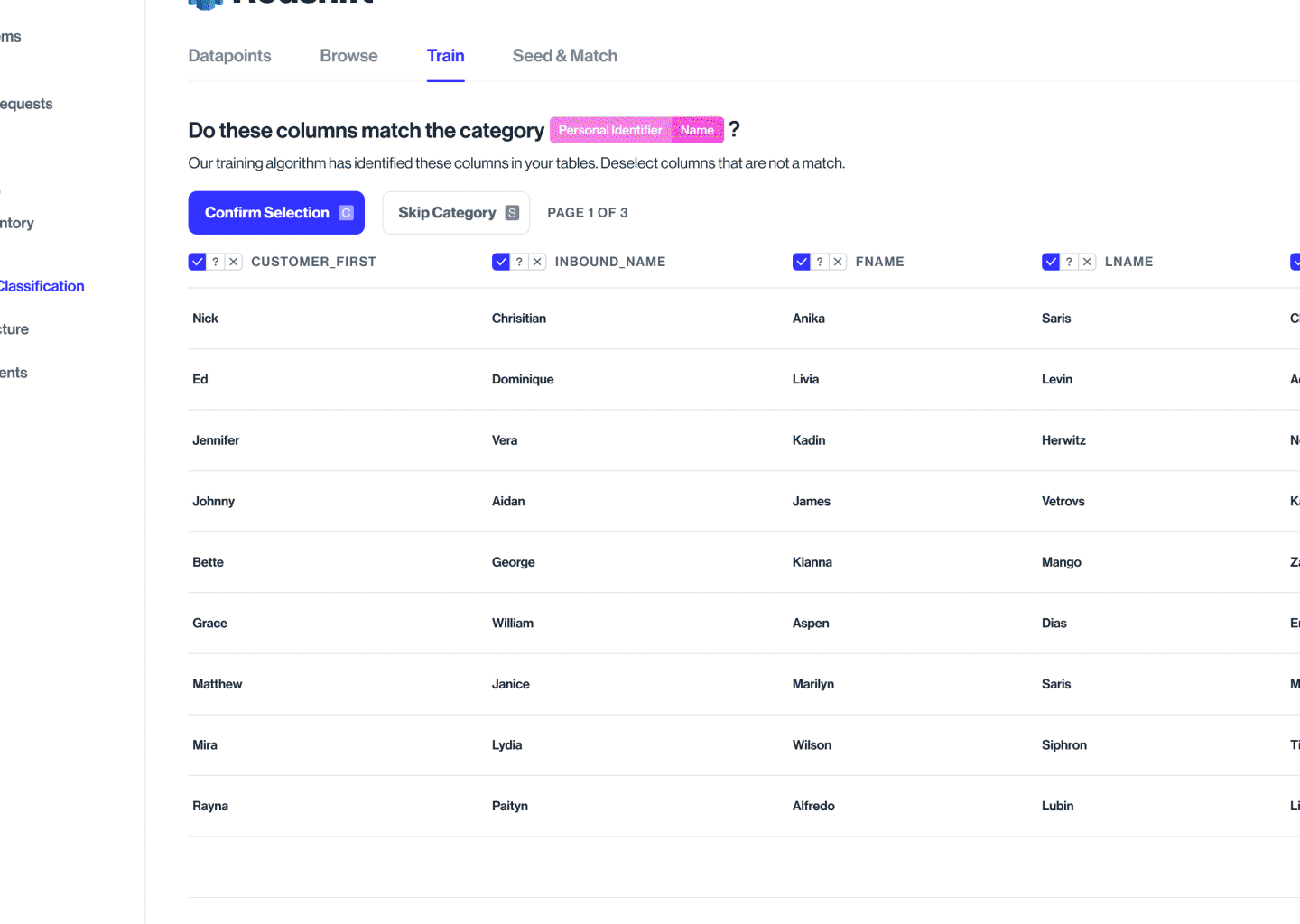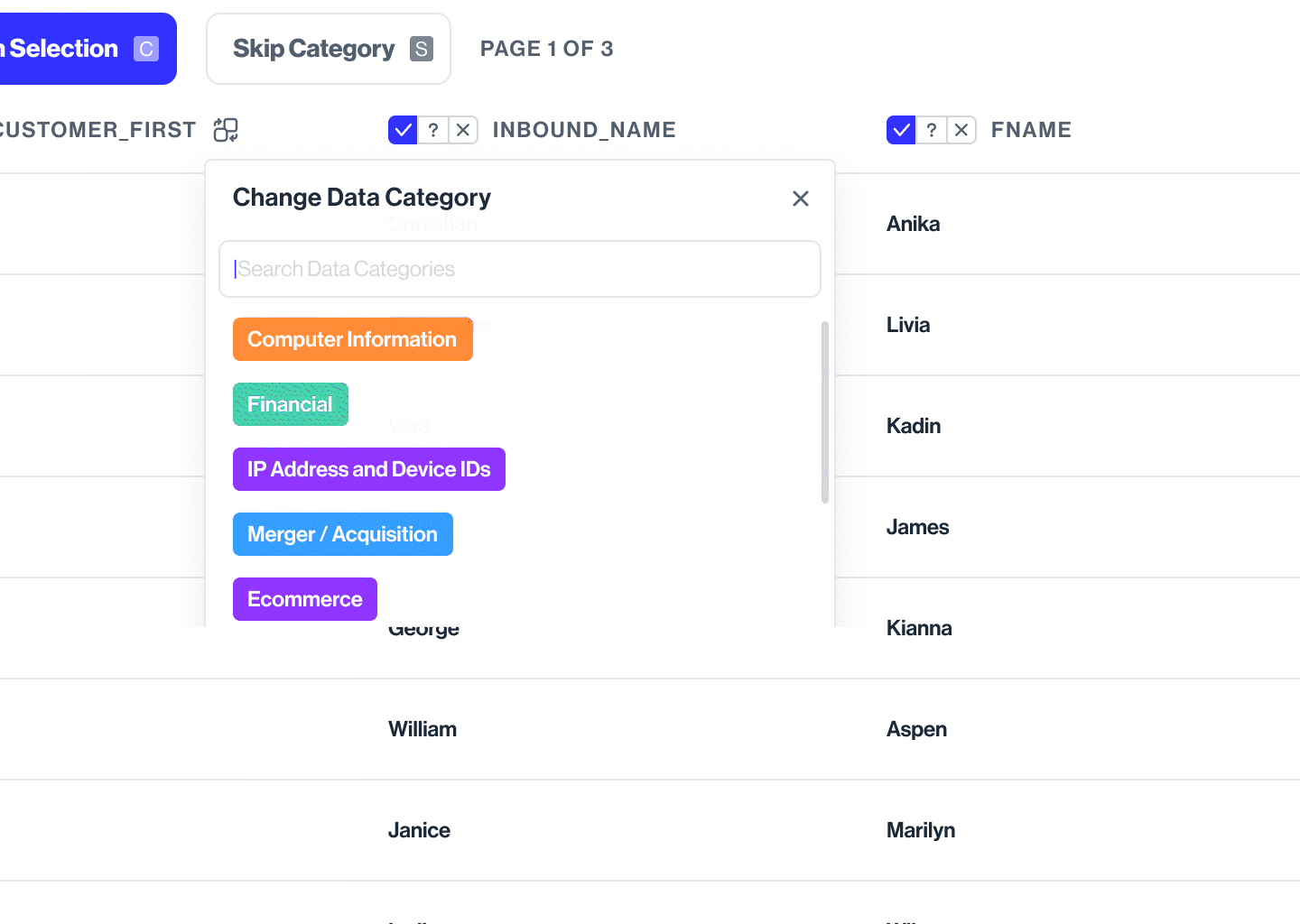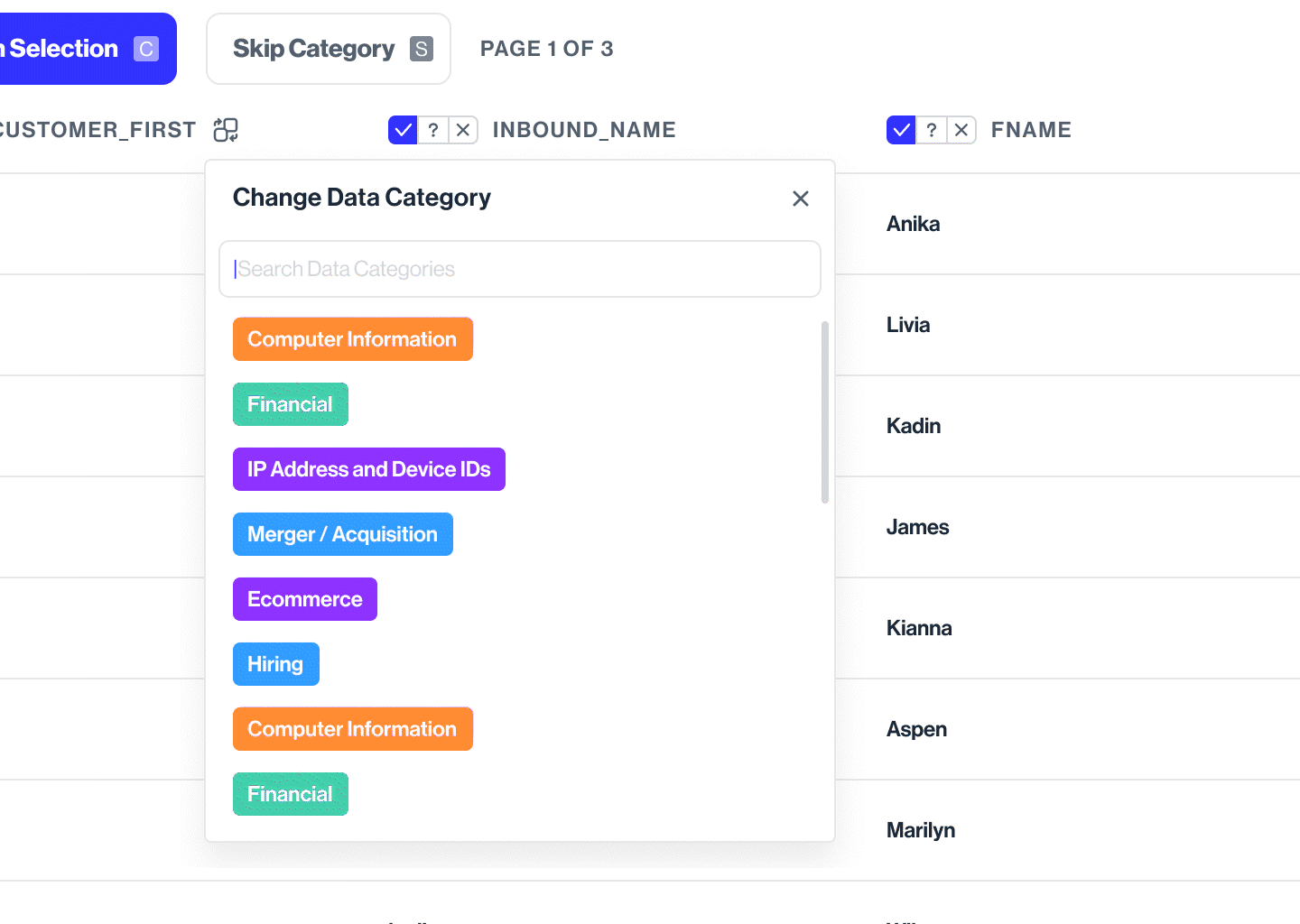
Training a particular datapoint, not the whole database/silo
Post training
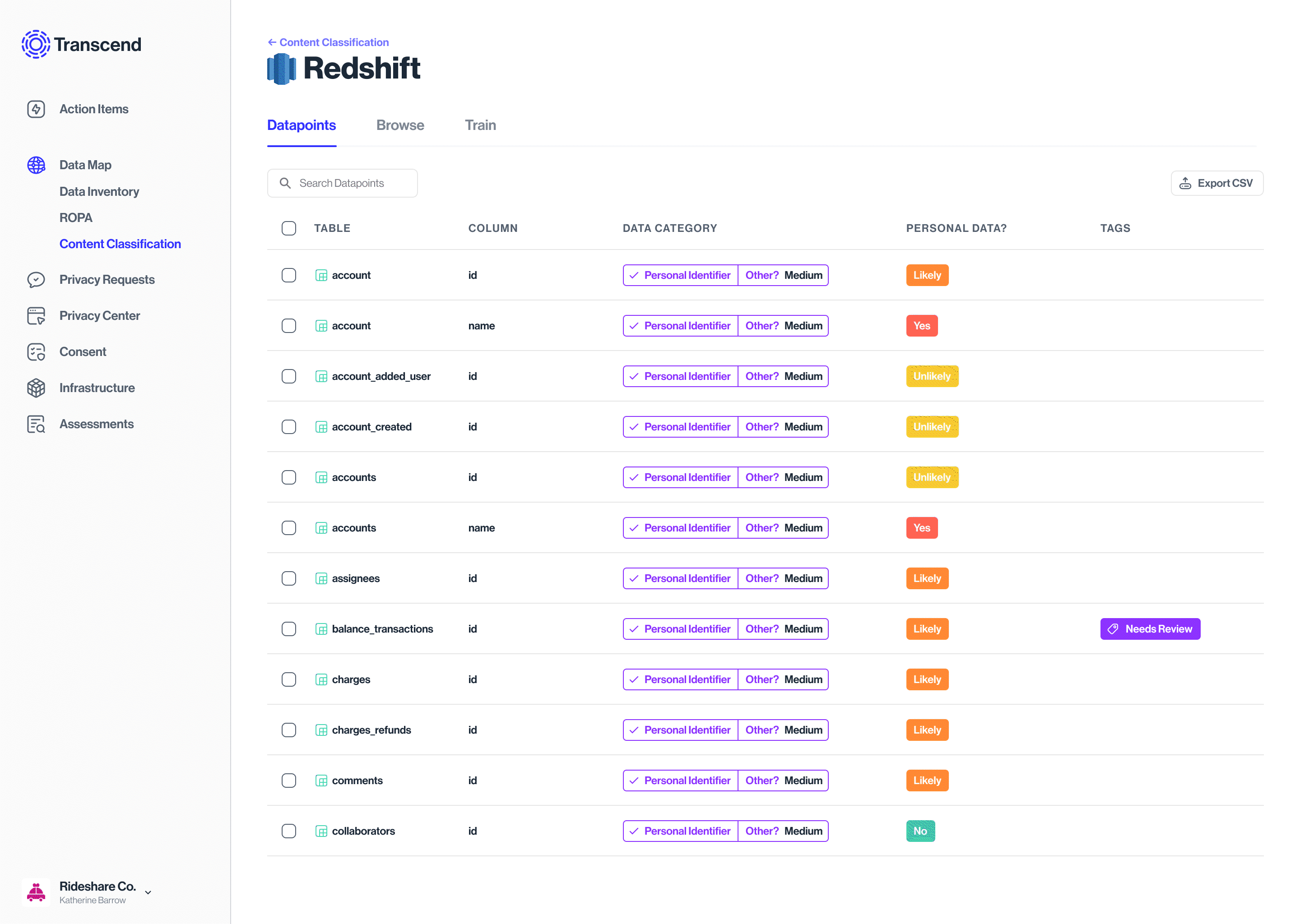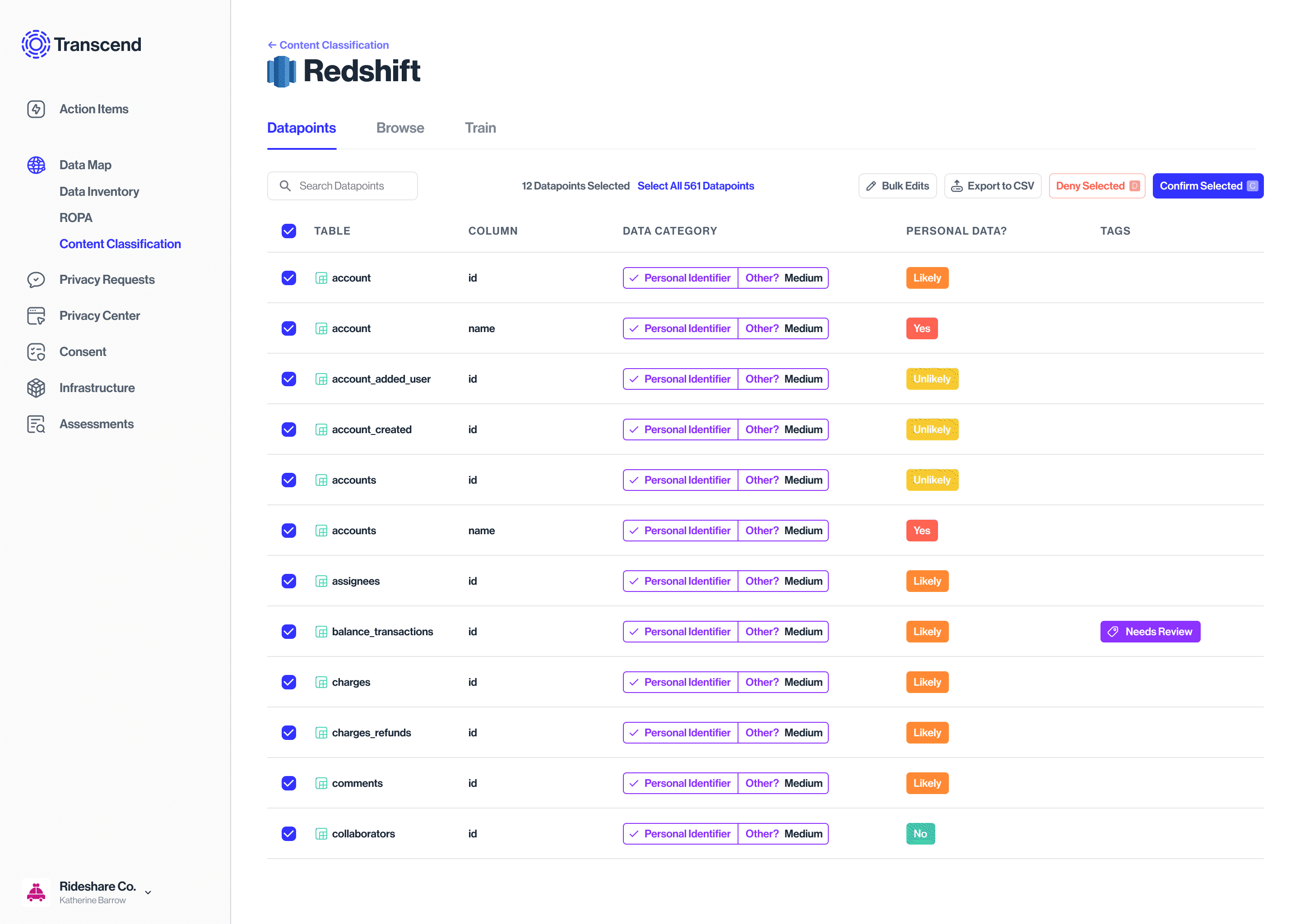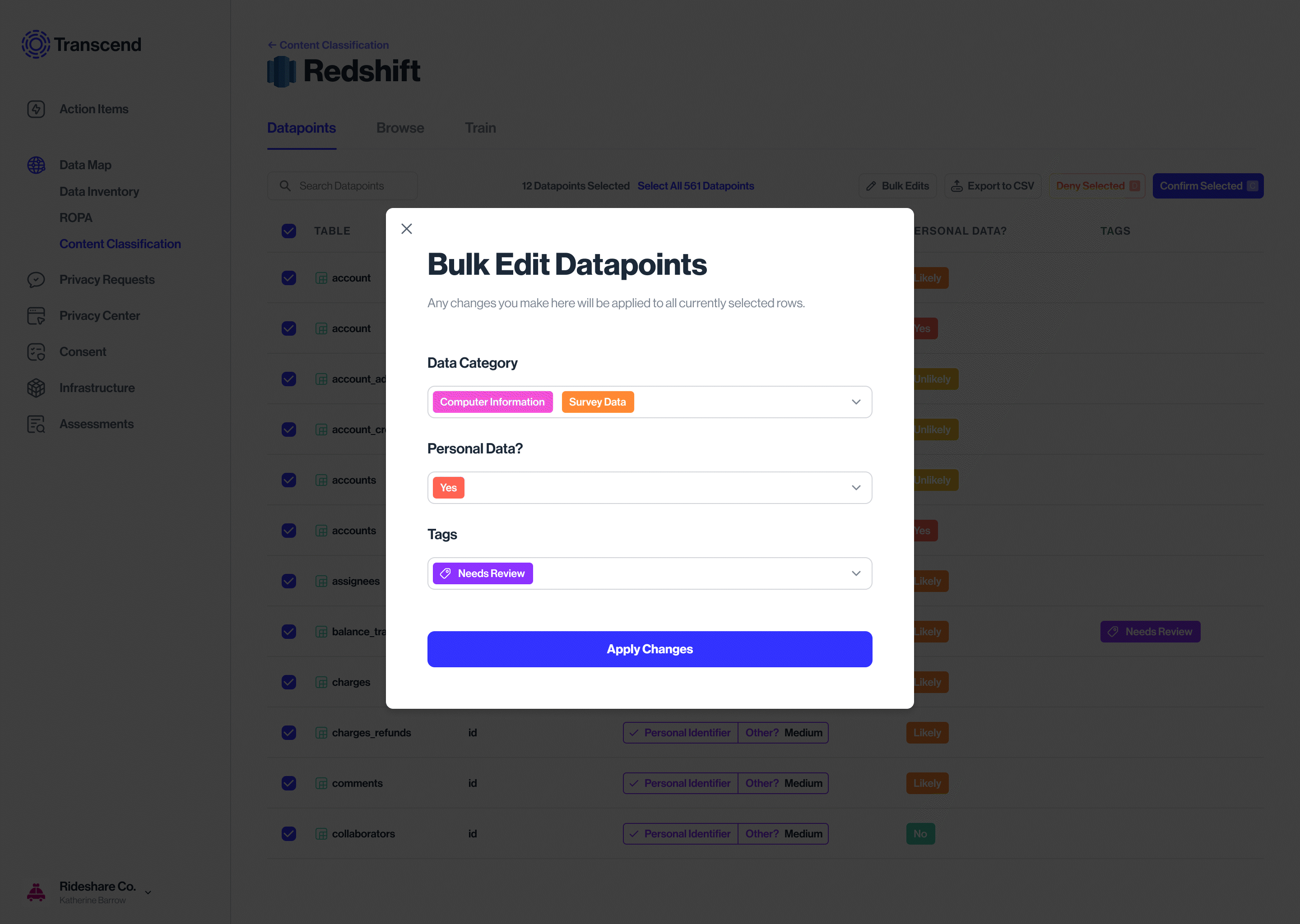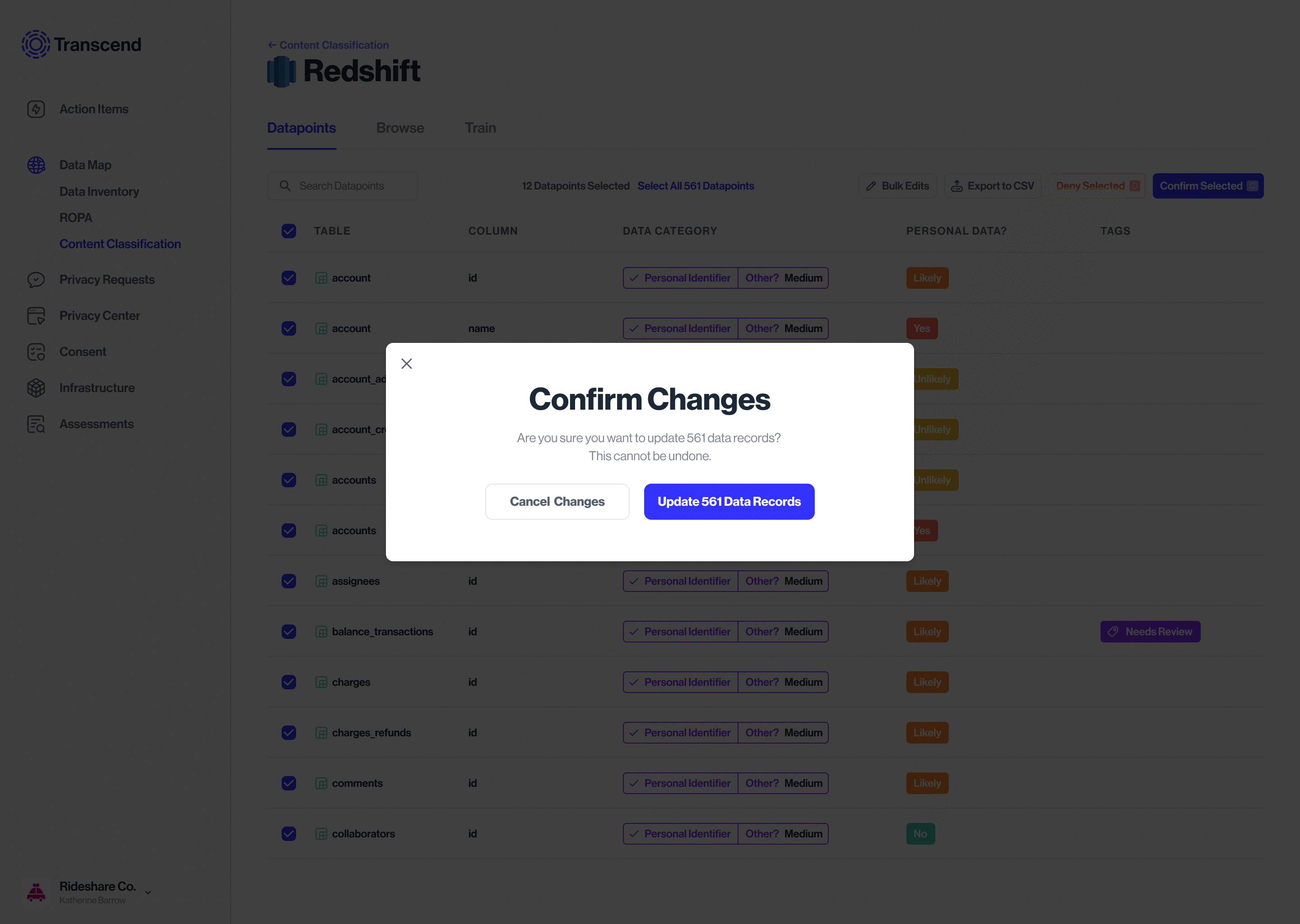
The model assigns confidence levels to the datapoints classification
Which the Data analyst can browse, & adjust
Bulk edit action for Datapoints
Single Datapoint edit
Outcomes
The Business impact
As at 2023, the launch year, 2/3 of all Transcend customers use this brand new feature.